Seguro que más de uno le debe la vida a haber sabido hacer un intérprete de una calculadora ampliada. Cuando vaya mejor de tiempo haré las presentaciones oportunas al resto de los mortales, así como introducciones teórico-prácticas acerca de cada aspecto y posibles variantes, pero vayamos al grano.
Queremos que, dada una entrada, el programa reconozca los componentes de la entrada, la estructura sintáctica de la misma, y genere unos resultados. Por ejemplo, queremos que en
a = b + 4
Sepa que hay un identificador llamado "a", un espacio, una operación de asignación, otro espacio, un identificador llamado "b", otro espacio, una operación de suma, otro espacio, un entero con valor cuatro, un salto de línea y un fin de la entrada. Además, queremos que sepa que eso significa que estamos intentando asignarle al identificador "a" el valor resultante de sumar el valor del identificador "b" y 4. Y encima queremos que lo sume y lo asigne.
Bien, de esta forma tan superficial ya tenemos diferenciadas las tres fases del análisis del intérprete: léxico, sintáctico y semántico.
Para facilitar la visualización, a la fase léxica le asignaremos el color verde, a la sintáctica el amarillo, y a la semántica el violeta.
Vamos a empezar, sin embargo, por una "fase 0" (color blanco) que utilizaremos para que almacene la línea de entrada, un contador que nos indique en qué posición de la línea estamos, un método que nos devuelva el carácter que hay en dicha posición y un método que nos permita volver atrás en esa línea (para poder recuperarnos en caso de error, y seguir analizando por donde lo dejamos).
Un ejemplo de esto: Supongamos que queremos asignarle a "a" la cadena "cadena", pero por lo que sea la hemos escrito mal y se nos han olvidado las últimas comillas. El programa recibe lo siguiente:
a="cadena
Para un correcto funcionamiento, debería ir diciendo
a="cadena
^
-Me he encontrado un identificador llamado "a"
a="cadena
-^
-Me he encontrado un operador de asignación
a="cadena
--^
-Me he encontrado unas comillas, así que puede que todo lo que venga a continuación sea una cadena
a="cadena
---^
-Me he encontrado una c, seguramente parte de la cadena
a="cadena
----^
-Me he encontrado una a, seguramente parte de la cadena
...
a="cadena
--------^
-Me he encontrado otra a, seguramente parte de la cadena
a="cadena
---------^
-¡Ojo! Me he encontrado con un salto de línea, pero esto no lo permito en las cadenas, así que daré un error (diré que el causante ha sido las primeras comillas), volveré atrás hasta el punto siguiente al error, y continuaré analizando a partir de ellas.
a="cadena
---^
-Me he encontrado un identificador llamado c
a="cadena
----^
-Me he encontrado una a, seguramente parte del identificador
...
a="cadena
---------^
-Me he encontrado un fin de línea, así que el identificador se llamaba "cadena"
-Me he encontrado con un fin de la entrada
Llamémosle al grupo anterior (el que guarda la entrada, la posición de la línea sobre la que nos movemos y permite mover atrás esa posición) la "caja flujo":

Vamos al siguiente paso: el analizador léxico. El analizador léxico será otra "caja" que albergará en su interior la caja de flujo, y le irá pidiendo el siguiente elemento en la línea para tratar de asociarlo con una serie de categorías predefinidas. Por ejemplo, intentará asociar las letras seguidas de más letras o números a la categoría "identificador", los números a la categoría "entero", etc. Si no puede asociar una parte de la entrada a ninguna categoría, dará un error léxico diciendo qué parte de la entrada no se esperaba. Si sí que asocia correctamente la entrada a una categoría, devolverá esa categoría, con la información suplementaria que sea necesaria (por ejemplo, el nombre del identificador, el valor del entero o de la cadena...)
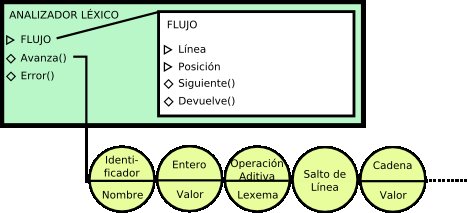
Recapitulando, con cada llamada al método "Avanza()", el analizador léxico irá pidiendo carácteres al Flujo (invocando a su "Siguiente()") para intentar construir el componente válido más largo posible (la llamada "estrategia avariciosa"). Una vez lo tenga, lo devolverá.
La siguiente fase es el análisis sintáctico. Igual que antes de emprender el análisis léxico necesitamos haber diseñado previamente la serie de categorías que vamos a contemplar, y cuál es su expresión regular (la forma que tendrá: números, letras seguidas de números, cadenas delimitadas por comillas, símbolos matemáticos, carácteres de control...), para el análisis sintáctico necesitamos haber diseñado previamente la gramática: cómo se construirán "frases" correctas.
Por ejemplo, en este lenguaje,
4+4
tiene una estructura correcta, pero
4 4 +
no la tiene (la podría tener si, por ejemplo, el lenguaje interpretara una calculadora de notación polaca, pero no es el caso).
La gramática de SiMPLe no es demasiado complicada; una operación asociativa a derechas se puede transcribir como algo así:
A -> B (( op A ) | lambda )
y el resto son casi todas del tipo:
A -> B ( op B )*
La razón de no hacer en la primera A -> B ( op A )* es que se generaría una ambigüedad (podríamos crear terminal op terminal op terminal a partir de producciones distintas). Sí podríamos hacerlo si, por ejemplo, tuviera la forma
A -> B ( op [ A ] )*
ya que no hay posibilidad de equívoco posible en las producciones seguidas para obtener cadenas como terminal op [ terminal op [ terminal ] op [ terminal ] ]
No profundizo en la gramática por no ser el objeto de esta entrada; quizá en la revisión detalle algunos aspectos de su funcionamiento. De momento, basta con decir que hay que asegurarse que la gramática no sea ambigua (y para esto hay que construir su tabla de análisis). Ojo con la tabla de análisis de una Gramática con Partes Derechas Regulares, que tiene un par de "añadidos" a la forma de hacerlo con una LL1. Hay ejemplos en los apuntes de la asignatura E79-II26 Humor Amarillo.
Retomando el hilo, el análisis sintáctico se limitará a ir pidiéndole al analizador léxico un elemento tras otro, e irá comprobando que los elementos que va recibiendo concuerdan con alguna de las estructuras preestablecidas que espera encontrar (comenzando por el análisis de la estructura-base "línea"). De no ser así, emitirá un error sintáctico.
El método invocado para analizar la línea llamará a su vez a otros métodos (según la serie de componentes que vaya encontrando) para analizar, por ejemplo, declaraciones de variables, impresiones, sumas, multiplicaciones, factores...
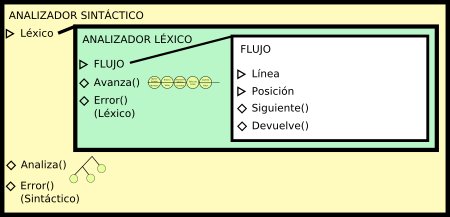
Una vez aquí, sabremos si una línea está bien formada o no. Pero, ¿cómo podemos darle sentido a la línea, para poder ejecutarla? Para esto modificaremos ligeramente la "caja sintáctica", ayudándonos de su estructura para crear un esquema de traducción dirigido por la sintaxis.
La idea es que cada rama del árbol correctamente analizada en el sintáctico devuelva una estructura (concretamente un Árbol de Sintaxis Abstracta) que, además de contener la estructura de las ramas-hijo, tenga una serie de métodos que le permitan comprobar su integridad semántica (no se pueden sumar enteros con cadenas, por ejemplo, ni asignar un valor a una variable no declarada; esto serían errores semánticos), ejecutar las operaciones correspondientes a cada rama, e incluso visualizar el árbol representándolo en forma de texto.

Los AST de tipo básico (enteros, cadenas) no tendrán AST hijos; además, no necesitarán comprobación semántica, y su ejecución es tan sencilla como devolver el valor almacenado en su componente (que se lo tendremos que haber hecho llegar a partir de su construcción en el sintáctico, que recordemos que a su vez lo habrá adquirido del léxico). El otro tipo "básico", el identificador, tampoco tendrá AST hijos, su comprobación semántica consistirá en averiguar si el identificador estaba declarado o no, y al ejecutarlo devolverá el valor que tuviera asociado (al ejecutar la declaración de variables, se habrá creado una entrada en un diccionario, con su nombre como clave, y su valor se habrá inicializado a 0 si la declaración era de tipo entero o a la cadena vacía si era de tipo cadena; aparte, también habrá guardado de qué tipo es dicha variable).
El resto de AST comparte básicamente la misma estructura: tienen uno o dos hijos (excepto el nodo de impresión, que puede tener varios), se guardan el tipo resultante de la operación correspondiente (si es entero, cadena o ha dado un error), algunas (asignación y automodificador) se guardan el i-valor del árbol izquierdo, sobre el que efectuarán las operaciones pertinentes durante su ejecución. Las comprobaciones semánticas consistirán, primero, en invocar a las comprobaciones de sus hijos (por si hubiera un error en éstos, que se detectara antes) y después hacer la comprobación de la operación propia. Para las ejecuciones, es similar: primero ejecutaremos los hijos izquierdo y derecho (en ese orden, como en las comprobaciones semánticas, para conseguir una correcta ejecución de izquierda a derecha), guardando los valores resultantes. Después, aplicaremos la operación pertinente a esos valores obtenidos.
En este punto, todavía podemos tener errores de un cuarto tipo: errores en tiempo de ejecución. Por ejemplo, una división por 0, o una replicación de una cadena un número negativo de veces. En este módulo trataremos convenientemente estos casos, según nos indiquen las especificaciones del lenguaje.
El método de declaración sólo tendrá sentido en el AST del Nodo de declaraciones de variables. Lo que se hace en él es lo mismo que habría que hacerse en su ejecución, sólo que lo hemos separado porque la especificación del funcionamiento del lenguaje así lo requiere. Este método no hará nada en el resto de AST, y en este AST el método ejecutar será el que no haga nada.
Así pues, el programa al completo tendrá esta estructura:
El resultado de crear este esquema de traducción dirigido por la sintaxis será algo similar a esto:
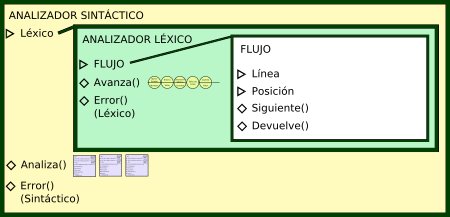
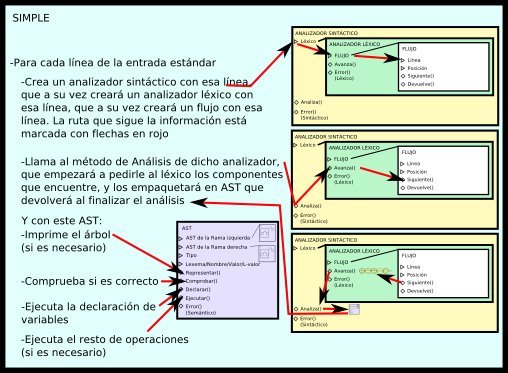
De forma que ya sólo nos queda utilizar toda esta estructura desde nuestro programa principal. Éste consistirá en un bucle que leerá líneas de la entrada; para cada línea, creará un analizador sintáctico que la analice, y guardará su AST resultante. Después, ejecutará los métodos pertinentes de este AST.
En el caso de que haya un error de cualquier tipo (léxico, sintáctico o semántico), las órdenes posteriores a donde haya saltado el error no se ejecutarán, pasando directamente a la siguiente iteración del bucle, con la siguiente línea (es decir, ante un error léxico o sintáctico no se construirá el AST, y ante un error semántico no se llegará a declarar variables ni ejecutar). A la hora de implementarlo, podemos conseguir este funcionamiento en Python encerrando el bucle anterior en un try-except, y elevando errores desde las funciones de error. Por supuesto, sólo es una de las muchas posibilidades.
Para cualquier aclaración, corrección, o lo que se tercie, aplicad comentarios ;)
Recuerdo que tengo intención de ampliar las explicaciones de cada fase, haciendo un pequeño resumen de lo que podemos encontrar, de forma mucho más profunda, en los apuntes de clase.

12 comentarios:
Menudo rollo, ¿no?
:D
Comparado con comer crêpes con chocolate... sí.
Dios bendito que currada.
Prefiero esta explicación tuya y eso que no he tenido fuerzas de leerla toda porqué con una calculadora SiMPLe (eso dicen ellos) he tenido sufiente, a todo un capitulo de los apuntes de procesadores de lenguaje. Pero cuidado no poner código que igual se enteran y te censuran ;)
¿Porqué tendremos que aguantar estas cosas señor?
Weno aupa con la protesta.
Como habrás adivinado he sufrido como tu a SiMPLe.
/* sense */
:-P
Mmmm que interesante.
¿os piden SiMPLe en python? No conozco las bondades de este lenguaje, pero me parece que no deja de ser un lenguaje interpretado, ¿no? ¿No hará esa que SiMPLe sea lentillo ante tanta carga de proceso? Quiero decir que las funciones que más tardan en ejecutarse en un programa en C son las de trabajo con cadenas, pero aún así son mucho más rápidas que Perl (en el caso que yo conozco).
A parte de esto me ha gustado mucho leer este post y ver este otro modo de conspirar :)
Recuerda, el único enemigo bueno es el enemigo muerto.
Más lento es el usuario escribiendo la entrada (es interactivo) ;)
La velocidad no es algo que prime en este trabajo; sólo se busca aprender cómo funcionan. Y es también la única motivación de la entrada, porque hay gente que sigue estando perdida, y no me parece justo guardarme lo que sé para mí solo, si puedo aportarlo al resto. No es por fastidiar a nadie, al contrario.
¡Un saludo! (Y muy buena la entrada del Zanguango :D)
Ahora a esperar las "specs" del compiler. ¿Será "Complex"?
CoMPLeX... buena idea XD
en realidad tengo ganas de hacer la asignatura ya... o mejor dicho, de saber lo necesario para poder hacer lo que piden, porque visto lo visto no está muy bien la cosa.
De todas formas, muy interesante :)
Espartaco Complex no le han llamado Comp´06 aupa con la originalidad. Al menos se ha obiado el termino simple, que ojito con la guasa. Será simple cuando sabes como lexe se hace. Porqué puedes darte cuenta que tu gramática no es GPDR después de entregarlo y ver la gramática que han puesto en el tal minicomp. ¿Y les costaría mucho decirmelo cuando lo ven? Porqué es que para más inri yo ponía antes de la cabecera de la correspondiente función analizaX la línia de la gramática con la que se correspondía. Y no será porqué no le he preguntado veces.
Eso si criticarme a mis espaldas si que sabe. Que la UJI es pequeña y uno se entera de todo. Y eso que no me han querido decir el comentario al respecto para no herir mi sensibilidad, se ve. Pero esa se la guardo a la persona que va por ahí difamando
Hace como 4 años que tengo la asignatura de Procesadores de Lenguajes atragantada (para más coña, ésta y el Proyecto es lo único que llevo este curso) y explicaciones como la tuya me vienen genial para ordenar las ideas e intentar afianzar una visión de conjunto.
Gracias, gracias, gracias...
Pues mucho ánimo. Al final, no seguí con la entrada y se quedaron muchas cosas por explicar, pero si algo aprendí en la asignatura es que estás pagando por una docencia decente, así que exígela. Pregunta sin cuartel, y quema y saquea hasta que obtengas una respuesta que entiendas a la perfección. Si no es así, el profesorado estárá cobrando sin hacer bien su trabajo.
Publicar un comentario